

Have you ever wondered how a giant like Netflix keeps its 200 million paying customers happy? By happy I mean providing 700 000 hours of streaming video every minute without serious glitches or significant interruptions. Achieving resilience in something as complex as Netflix architecture is not an easy task and has to be baked into the system itself. Have a look at this high-level services snapshot:
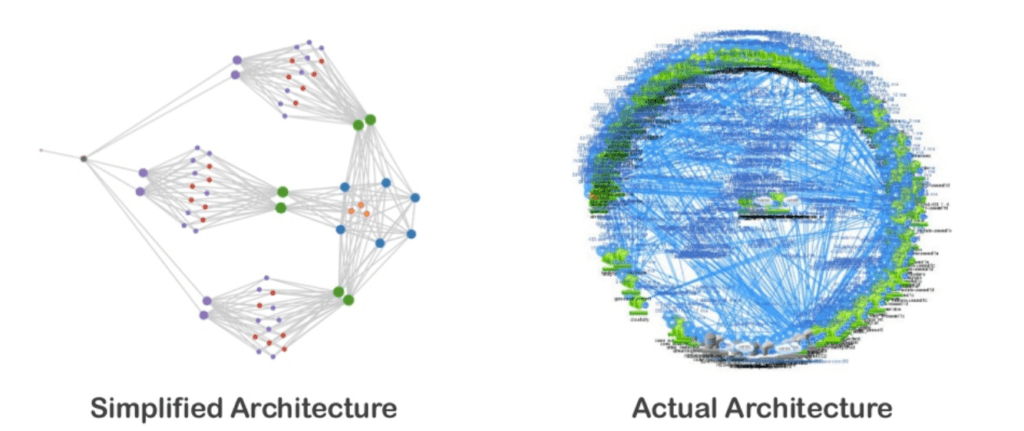
What would you do to ensure reliability and continuous change flow in a system like this? Don’t know about you but I know what I definitely wouldn’t do, and that’s employing an army of monkeys to help me bring stability to the system. But then who am I to question choices of Netflix tech gurus… Because that is exactly what they decided to do. The idea was to shift developer’s mindset from the one where they assumed no breakdowns to one in which breakdowns were inevitable. This way Netflix could still cultivate their freedom of choice in their dev teams without global rules damaging their independence and sense of responsibility. In other words, they didn’t want to force developers to code in any specific way, but they still expected code to guarantee resilience at scale.
The Simian Army
Netflix understood that simple and even advanced service and deployment monitoring will not suffice at their scale. The demand for change was too rapid and teams were many. The solution was… introducing a bit of chaos, or instability to the CI/CD pipeline, today we call it the Chaos Engineering. It was a radical approach to continuous delivery first described by Greg Orzell who was overseeing Netflix migration to the cloud back in 2011. Netflix created a set of tools constantly messing with system stability, randomly killing services both in development as well as production environments. This toolset grew and evolved with time and is now called the Simian Army.

At the core of the Simian Army are 10 (helpful?) individuals each representing a specialized tool for a very specific task category. Without further ado let’s meet our celebrity monkeys:
- Chaos Monkey – Basically kills random service instances as it sees fits.
- Chaos Gorilla – This one kills entire zones of services.
- Chaos Kong – As you can imagine this will be killing on an even higher level, it works on whole regions.
- Latency Monkey – It deals with network degradation and network fault injection.
- Conformity Monkey – Check application instances against a set of customizable rules (can check scaling configurations)
- Security Monkey – Finds and disables instances that have known vulnerabilities.
- Circus Monkey – Kills and launches instances to maintain zone balance.
- Doctor Monkey – Fixes unhealthy instances.
- Howler Monkey – Yells about various violations like AWS limit violations
- Janitor Monkey – Clean up unused resources.
If you would like to get to know our heroes a bit more I can recommend a great book by Antonio Garcia Martinez called “Chaos Monkeys”, here is a bit of a spoiler free quote from the man himself:
“Imagine a monkey entering a ‘data center’, these ‘farms’ of servers that host all the critical functions of our online activities. The monkey randomly rips cables, destroys devices and returns everything that passes by the hand [i.e. flings excrement]. The challenge for IT managers is to design the information system they are responsible for so that it can work despite these monkeys, which no one ever knows when they arrive and what they will destroy.”
Monkeys in the cloud
Do you think your project is ready for this level of chaos? If you think it is not, then you will very likely benefit from it. I am not suggesting you should start messing with your live system straight away. If you are however, not willing to introduce a bit of chaos into your development pipelines then you are inviting it to the production to be reported by your end users.
If you would like to give Chaos Engineering a try, below are some helpful tools you may want to research:
- Chaos Mesh – Open source chaos engineering tool for Kubernetes environments. Capabilities include network failures, pod and container failures, file system failures and even Linux kernel failures like slab and bio.
- Gremlin – A failure-as-a-service platform. Fully hosted solution supporting bare metal, any cloud providers, containers, Kubernetes and serverless.
- ChaosToolkit – Its goal was to simplify Chaos Engineering. CT is an open source platform that promotes declarative experiments at the same time providing ease of integration with CI/CD or hosting providers.
- Litmus – A chaos framework focusing on Kubernetes workloads. It supports the idea of experiments that can be downloaded from a centralized hub here.
To Monkey or not to Monkey: The Cost-Benefit Analysis
Like almost every question in systems architecture, the question of whether you should go the Chaos Engineering way can be answered with the famous “It depends”. It is, however, much easier to see what it depends on when you realize what the cost and benefit are. In this article from IEEE, Netflix experts talk about business cases for introducing Chaos Engineering and explaining its cost-benefit analysis to stake holders. In a nutshell it boils down to costs of establishing a CE team as well as costs of potential impact the simulated outages may have. The benefits are mainly in form of money saved by outages prevented by CE. Key thing to remember is that chaos induced failures should have orders of magnitude with smaller impact on your system than the actual failures it can prevent. If you like to crunch some numbers, below is an example formula described by Netflix Experts in their article with the actual (fictional) scenario:
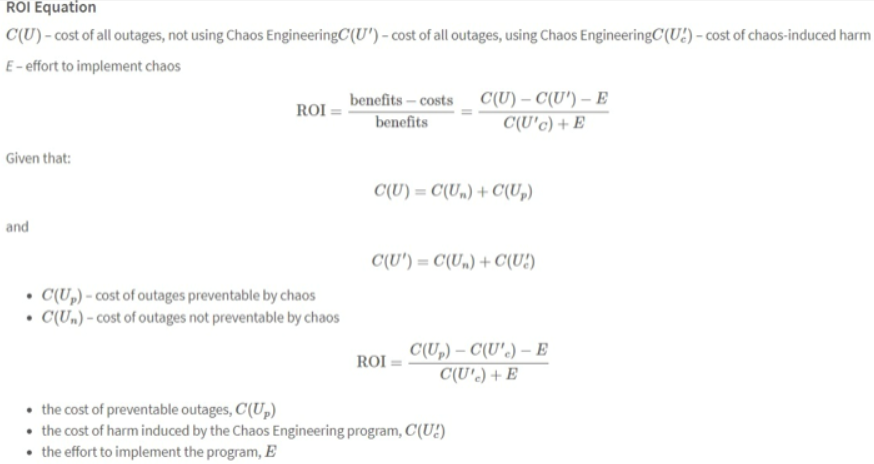
And here we can see it with some real numbers:

I hope by now you have some understanding of what Chaos engineering is and how it could potentially help bring high resilience to your system. As always please share your thoughts in the comments below.